Investors
Investment overview for FRC: what it is, what is measured, and what is being built next.
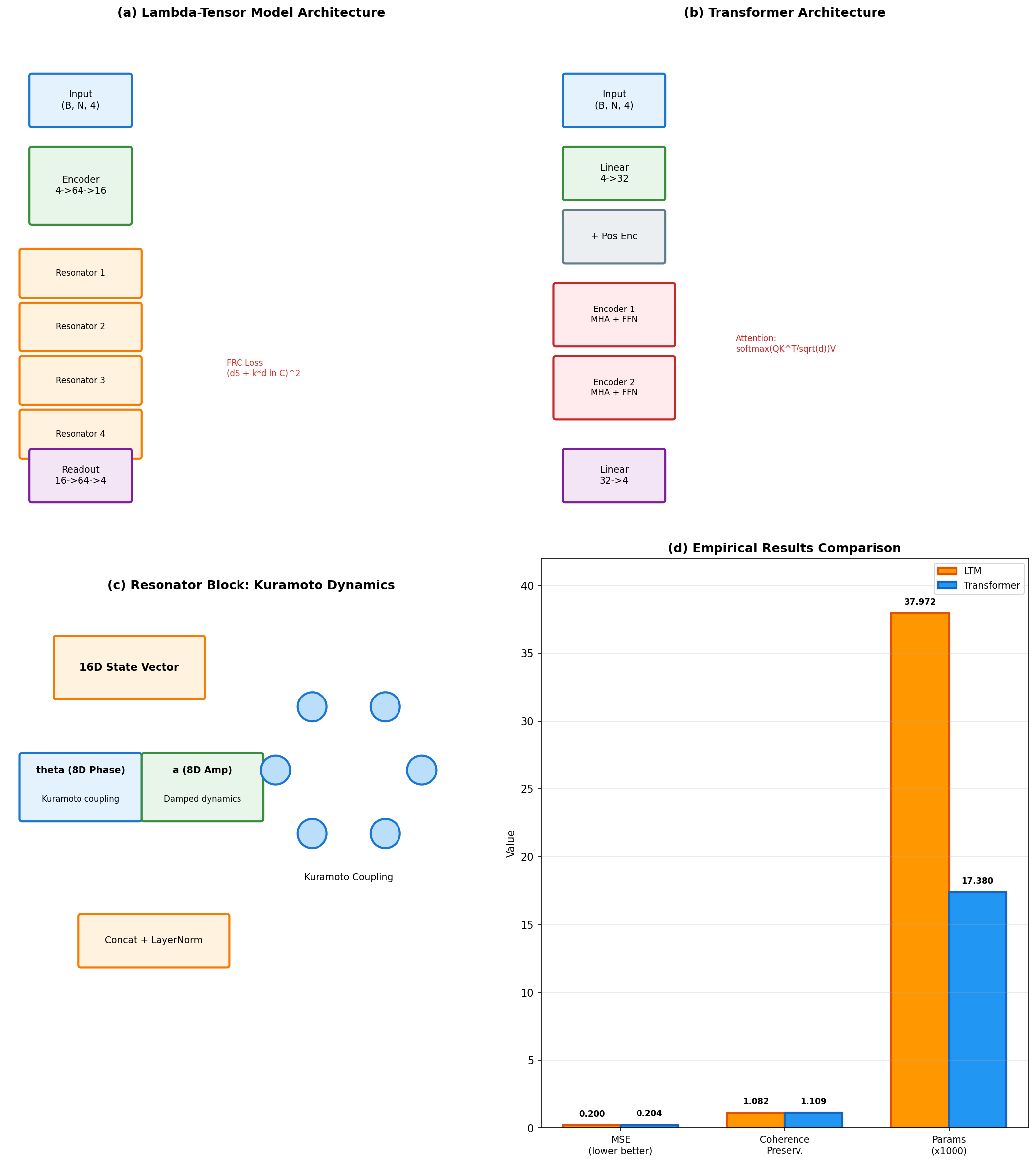
Tokenization and discrete attention are excellent abstractions for text, but they discard phase and continuous structure. FRC proposes resonance-native representations and architectures for phase-coherent domains.
The canon is published as numbered papers with stable IDs and explicit hypotheses. The current AI track is the Λ‑Tensor Model (LTM) and its empirical benchmark versus attention on phase-coherence tasks.
With agentic workflows + retrieval, we can maintain a rigorous corpus, run repeatable experiments, and iterate on architecture without corrupting the reference layer.
FRC-840-001
The Engine (LTM): attention → resonance.
FRC-16D-001
Protocol: Universal Vector for cognitive state.
FRC-840-LTM-001
Empirical: LTM vs Transformer on phase coherence.
What we’re building next
- - More empirical benchmarks in oscillatory domains (audio, biosignals, control).
- - A clean SDK + task dispatch system for repeatable research pipelines (SOS).
- - A “mirror memory” subscription layer for personal AI workflows (Mumega).
What to evaluate
- - Can LTM reproduce the benchmark with a minimal training script and fixed seeds?
- - Does the approach generalize beyond the published task to adjacent phase-coherent domains?
- - Is the canon structured enough for agents to cite (IDs), retrieve (graph), and not hallucinate?